
Introduction
One of the biggest challenges when testing in a project that involves personally identifiable information (PII) is the test data. It may be possible to use some data from the production environment and still respect GDPR, but in most cases, production data is not available for the testers’ use.
Most severely affected by this are performance tests, which need adequate volumes of representative data, used by the different functions of the system, in order to obtain valid measurements. As we will show in this article, a good test data strategy, along with an effective set of data generation techniques, can help to address these challenges.
Why is representative test data important?
As we have said, a major challenge in testing is obtaining a good test dataset.
For functional testing, a lot of the effort is often in identifying and creating test data for the unusual ‘corner’ cases. Whereas, when trying to reproduce a defect from production, the difficulty is knowing what aspect of the dataset is needed to illustrate the problem without having access to the production dataset.
Non-functional testing complicates the situation further, especially when undertaking performance testing. Here, we need a large volume of data, which supports realistic scenarios that accurately simulate key user journeys, to determine if the application can handle the data volume while achieving the required performance. It is rarely possible to do performance tests in the production environment since they are very disruptive. This means that the datasets in our test environments need to have very similar characteristics to the data found in production so that we can perform representative tests.
In summary, without sufficient test data, the result is a plethora of defects not being found until they appear in production, thus increasing the disruption they cause and the cost of fixing them.
However, let’s not forget that creating good-quality, representative test data can result in significant costs in the development and testing work, which might get overlooked given today’s emphasis on ‘shifting left’ and performing testing activities earlier in the development life cycle.
Metrics for test data relevance
The process of acquiring test data is often not as easy as it may seem. There are generally two possibilities for procuring test data - gathering it from production or generating it ourselves.
A one-to-one copy of the data from the production environment seems like an obvious approach that ensures a representative dataset to test against. However, a lot of production data is very sensitive – think of medical records or financial data – and so, it is often simply not available for use in testing.
Therefore, we are left with the option of generating the data ourselves – so-called ‘synthetic’ test data. The immediate question that arises with this approach is how to identify a metric to determine how representative a synthetic test dataset is compared to the corresponding production data. The first step towards such a measure is to gather some metrics from the production dataset to characterise it.
Let’s take, for example, a database for a financial transaction processing system. Some of the things we could usefully measure without access to the actual data include:
- Number of transactions per time unit (hour/day/month/year) - whatever time frame is needed to make it relevant for the tests
- Number of users in the system, classified by user type
- Number of transactions per user in the time frame
- Distribution of the different transaction types per time unit and user
- Average values of key transaction attributes (such as financial value) with a minimum, a maximum and a standard deviation
- Number of countries/currencies supported and the average transaction distribution per country/currency
Obviously, it could often be valuable to add other, application-specific measurements, depending on the nature of the application and dataset.
To determine how similar any generated dataset is compared to production, run the same queries on both databases and compare the results. This is a good indicator if your data is close to production or not, thus having an overall metric for a ‘data resemblance factor’.
Data protection techniques
In situations where we can use production data, we will have to process it to protect any personal data in the dataset. The key techniques to consider include:
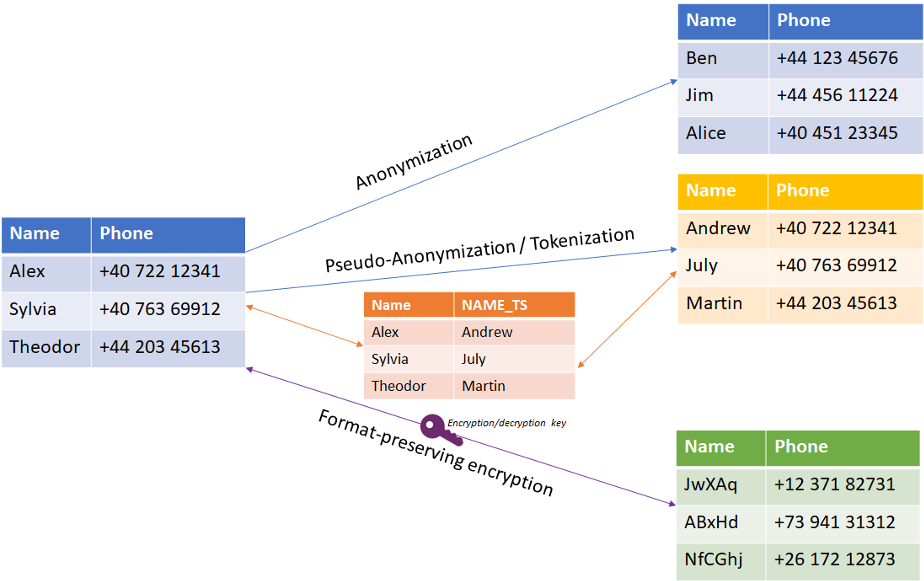
- Anonymisation – the use of randomisation and generalisation to replace PII with a realistic, generated value so that a record cannot be tied to any real-life person
- Tokenisation – a simpler process where the sensitive data is replaced with a placeholder value, but one that is more generic and does not necessarily preserve the original format
- Pseudo-anonymisation – a technique that uses a mapping table between the real PII data and randomised data to replace it, allowing the original data to be restored at some point if needed, but this requires that the mapping table is carefully protected
- Format-preserving encryption – encrypting the sensitive data in such a way that preserves the format so that the data is still relevant
- Synthetic data – entirely synthetic, generated data created for all fields in the dataset, generated in such a way that the format is correct and data linkages between the tables are still valid
A diagram representing how each technique works is shown below:
The most complex approach is using completely synthetic data, as this requires that the relationships between the data are created as well as the individual data values – and the dataset must respect the data constraints and foreign keys that link the tables. Creating data generator tools to achieve this is quite complicated and sometimes requires a lot of business logic to be implemented in the tool, which could make it unfeasible in some situations.
Test data generation strategy recommendations
While deciding what approach to use, the first thing you should clarify is whether production data can be used or not, and if so, whether it contains personally identifiable information.
If you can use production data, then you can identify the required amount and a strategy for extracting it from production. Next, the data protection techniques to use can be selected based on the protection level needed and the effort that the project can accommodate. Usually, anonymisation and format-preserving encryption can provide a cost-effective option.
Choosing the most challenging approach, synthetic data generation, will involve identifying the metrics to use for checking the match to the production dataset, writing the SQL queries to derive those values from a dataset and implementing the tool that generates the data. Keep in mind that this will have to meet the needs of the testing process but also accurately reflect the characteristics of the production data set.
Make sure that you remember to include the test data generation effort when planning the work and create explicit stories to allow it to be planned and scheduled. Without a good overview of what is needed in terms of creating the data, the overall testing process will be under pressure, and this will result in bottlenecks during development. Also, make sure that you are using the best approach for your situation to obtain the relevant test data and explain the effort needed to produce and manage it to your stakeholders.
PII and GDPR compliance in testing
The implementation of GDPR has resulted in data now having an increased significance for both the customer and the data processor. GDPR article 6 defines the laws governing data processing and enforcing the need for consent, based on a contract that was acknowledged by the participants and the legal obligations of the data processor, including safeguards for protecting it. This is also referred to in articles 25 and 32, where security is a mandatory activity while dealing with such data.
This means that using production data for testing purposes might violate GDPR guidelines if the customer did not give their consent for such usage. Article 5 defines the fact that data should be collected with fairness and transparency and must be adequate, accurate, limited and relevant, which requires companies to conduct measures to ensure the integrity and confidentiality of the data collected.
In addition, article 30 makes it clear that whenever a data processing event occurs, there should be a record of it.
The prevalence of PII in most databases, along with GDPR requirements, means that the use of production data by testers could pose imminent risks, as they could unintentionally share data using unsafe communication channels that could lead to data breaches. If a data breach occurs, it must be communicated to the data owner of the data as specified in article 34.
The GDPR regulations allow for extremely large fines to be imposed. We have already seen fines as large as $126 million (€100 million) being imposed in January 2020, and the sums could get even higher in the future. This is one of the reasons why it is so important that we all understand the fundamentals of GDPR and our responsibilities.
Conclusions
The process of generating test data itself comes with challenges, but adding security constraints on top of it only increases the cost of delivering test quality. There are some methods you can use in order to comply with the PII requirements that could be integrated into the overall process. Based on the data shape extracted from production, relevant new data could be generated and quantified using metrics that can increase confidence in the testing process.
Failing to produce relevant data could jeopardise the testing process, but failing to ensure GDPR compliance would result in potentially hefty fines and reputation loss.